 2.2 Computational considerations and comparisons
2.2 Computational considerations and comparisons
If the magnitude of the elements of the powers of 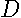 do not rise with the power, the power series converges rapidly. Note, row-stochastic, non-negative can have a maximum of 1 in any row. Hence, the magnitude of the elements in the powers of does not grow with the power. Given the rapid decline in the coefficients in the power series, achieving a satisfactory progression with six or seven terms seems feasible.
do not rise with the power, the power series converges rapidly. Note, row-stochastic, non-negative can have a maximum of 1 in any row. Hence, the magnitude of the elements in the powers of does not grow with the power. Given the rapid decline in the coefficients in the power series, achieving a satisfactory progression with six or seven terms seems feasible.
Straightforward implementation of the definition of  by a power series expansion truncated after
by a power series expansion truncated after 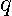 terms with
terms with 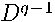 as the highest degree term would require
as the highest degree term would require 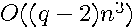 operations for dense , as matrix multiplication requires
operations for dense , as matrix multiplication requires 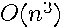 operations for dense matrices. This would not be practical and computing the matrix exponential using eigenvalues and eigenvectors would also be impractical for sufficiently large dense matrices, since this requires operations.
operations for dense matrices. This would not be practical and computing the matrix exponential using eigenvalues and eigenvectors would also be impractical for sufficiently large dense matrices, since this requires operations.
If the graph of is strongly connected, meaning that a path exists between every pair of observations, then 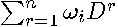 will be dense (all non-zeros) for positive
will be dense (all non-zeros) for positive 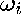 (Horn and Johnson, p. 361-362). Hence, will be dense. Computing separately would thus require prohibitive amounts of memory for large
(Horn and Johnson, p. 361-362). Hence, will be dense. Computing separately would thus require prohibitive amounts of memory for large  . Fortunately, one does not need to compute separately, as always appears in conjunction with
. Fortunately, one does not need to compute separately, as always appears in conjunction with  .
.
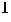 This allows computation of
This allows computation of 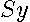 in
in 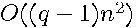 operations for dense by sequential left-multiplication of by to form
operations for dense by sequential left-multiplication of by to form 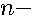 element vectors, (i.e.,
element vectors, (i.e., 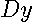 ,
, 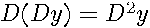 , and so on).
, and so on).
For sparse , that would result from a spatial weight matrix based on nearest neighbors computed using Delaunay triangles, or a sparse covariance structure based on the spherical variogram, the number of operations required to compute declines dramatically.
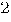 The number of operations required drops to
The number of operations required drops to  , where
, where 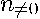 denotes the number of non-zeros. For the nearest neighbor spatial weight matrix approach with
denotes the number of non-zeros. For the nearest neighbor spatial weight matrix approach with 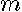 non-zero entries in each row, the operation count associated with computing would decline to
non-zero entries in each row, the operation count associated with computing would decline to 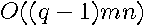 . This results in an operation count for computing in nearest neighbor specifications of that is linear in .
. This results in an operation count for computing in nearest neighbor specifications of that is linear in .
To illustrate this computation approach in detail, we define the x matrix 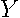 comprised of powers of times in (
5
).
comprised of powers of times in (
5
).
 | (5) |
Note that, this simple form of sparse matrix-vector multiplication can be implemented without explicit use of sparse matrix multiplication algorithms. Given a list of neighbors for observation  (i.e.,
(i.e., 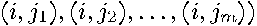 and given equal weights for the neighbors, the product for observation is merely (
and given equal weights for the neighbors, the product for observation is merely (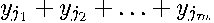 )/. That is, the sparse matrix-vector products needed to compute in (
5
) require only indexing and addition, two of the fastest operations possible on digital computers. This means that the MESS model can be implemented in a variety of computing languages such as FORTRAN or C, and various statistical software environments. In fact, to demonstrate the feasibility of estimating MESS using standard software we coded the estimator in Fortran 90 as well as in Matlab. Employing a compiled language (Fortran 90) plus using indexing as opposed to sparse matrices increased the speed by more than 6 times.
)/. That is, the sparse matrix-vector products needed to compute in (
5
) require only indexing and addition, two of the fastest operations possible on digital computers. This means that the MESS model can be implemented in a variety of computing languages such as FORTRAN or C, and various statistical software environments. In fact, to demonstrate the feasibility of estimating MESS using standard software we coded the estimator in Fortran 90 as well as in Matlab. Employing a compiled language (Fortran 90) plus using indexing as opposed to sparse matrices increased the speed by more than 6 times.
We provide a comparison of maximum likelihood estimates and the time required to solve the MESS model and a traditional spatial autoregressive model (SAR) taking the form:  , with a spatial weight matrix based on 30 nearest neighbors making it an asymmetric row-stochastic matrix. These comparative results were based on a dependent variable representing housing prices across 57,647 census tracts along with five explanatory variables described in section
3
. This comparison makes the point that the parameter estimates for
, with a spatial weight matrix based on 30 nearest neighbors making it an asymmetric row-stochastic matrix. These comparative results were based on a dependent variable representing housing prices across 57,647 census tracts along with five explanatory variables described in section
3
. This comparison makes the point that the parameter estimates for  in traditional spatial econometric models as well as inferences regarding the magnitude and significance of these parameters can be replicated using the MESS model. In this application the MESS model took the form:
in traditional spatial econometric models as well as inferences regarding the magnitude and significance of these parameters can be replicated using the MESS model. In this application the MESS model took the form: 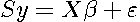 , where the explanatory variables matrix
, where the explanatory variables matrix 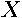 was not transformed for comparability with the SAR model.
was not transformed for comparability with the SAR model.
The estimates from both models are presented in Table
1
along with computed deviances that would be used to draw inferences about the statistical significance of each variable. These deviances reflect the change in the log likelihood arising from sequential deletion of each variable from the model.
>From the table we see that the parameter magnitudes are very similar from both models. Since the model is in log form, the coefficients can be interpreted as the percentage change in housing prices that would result from a one percent change in the explanatory variables. The deviances would produce the same inferences regarding the significance or lack thereof for all variables. (In this case, all of the explanatory variables are significant at the 0.01 level.)
The table also shows a timing comparison for computing estimates using the two methods, where we see a dramatic improvement in speed associated with the MESS model which is over 1,000 times faster than the more traditional SAR model. This speed gain was obtained in Matlab. The Fortran coding accelerated this already fast implementation by over a factor of 6.
 In section
2.5
we motivate that the computational speed of the MESS model allows quick hypothesis testing of alternative specifications for the functional form taken by the spatial weight matrix, as well as more traditional specification tests used in regression models. These testing methods are illustrated in an application presented in section
3
.
In section
2.5
we motivate that the computational speed of the MESS model allows quick hypothesis testing of alternative specifications for the functional form taken by the spatial weight matrix, as well as more traditional specification tests used in regression models. These testing methods are illustrated in an application presented in section
3
.

 Sidje (1998) has also used this as a point of departure in the computation of matrix exponentials. In addition, Sidje provides other algorithms for computing the matrix exponential right multiplied by a vector. Finally, Sidje provides software implementing these algorithms in both Matlab and Fortran 77.
Sidje (1998) has also used this as a point of departure in the computation of matrix exponentials. In addition, Sidje provides other algorithms for computing the matrix exponential right multiplied by a vector. Finally, Sidje provides software implementing these algorithms in both Matlab and Fortran 77.
 Myers (1997, p. 276) indicates the spherical model is the one most often used in geostatistical practice. See Barry and Pace (1997) for more about the use of sparsity with the spherical model.
Myers (1997, p. 276) indicates the spherical model is the one most often used in geostatistical practice. See Barry and Pace (1997) for more about the use of sparsity with the spherical model.
 The use of an asymmetric 30 neighbor spatial weight matrix poses a substantial computational challenge to computing the log-determinant term used in maximum likelihood. The times reported in Table
1
could be improved to around 400 seconds by using symmetric spatial weight matrix. The times would improve further if fewer neighbors were used or if the Monte Carlo Log-determinant estimator proposed by Barry and Pace (1999) were employed to compute the SAR estimates.
The use of an asymmetric 30 neighbor spatial weight matrix poses a substantial computational challenge to computing the log-determinant term used in maximum likelihood. The times reported in Table
1
could be improved to around 400 seconds by using symmetric spatial weight matrix. The times would improve further if fewer neighbors were used or if the Monte Carlo Log-determinant estimator proposed by Barry and Pace (1999) were employed to compute the SAR estimates.
