 2.5 Quick hypothesis testing
2.5 Quick hypothesis testing
Efficient computation of likelihood ratio tests requires updating the sum-of-squared errors matrix 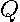 without recomputing the actual regressions. Let
without recomputing the actual regressions. Let  denote the
denote the 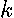 by
by 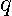 matrix of estimates from the regression of
matrix of estimates from the regression of 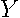 on
on 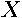 and let
and let  denote the
denote the  by matrix of errors from the regression. Expression (
17
) shows the restricted least squares estimate for
by matrix of errors from the regression. Expression (
17
) shows the restricted least squares estimate for  ,
,
 | (17) |
where 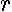 is a
is a 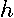 by 1 vector,
by 1 vector, 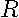 denotes a by matrix, and is the number of hypotheses imposed.
denotes a by matrix, and is the number of hypotheses imposed.
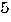
Let 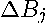 in (
18
) denote the change in the restricted least squares estimates versus the unrestricted estimates for the
in (
18
) denote the change in the restricted least squares estimates versus the unrestricted estimates for the  th regression.
th regression.
 | (18) |
The inner product of any two vectors of restricted regression errors appears in (
19
).
 | (19) |
where  represent the vectors of restricted regression errors and
represent the vectors of restricted regression errors and 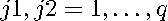 . Expanding (
19
) yields (
20
).
. Expanding (
19
) yields (
20
).
 | (20) |
where two of the possible terms vanish due to the enforced orthogonality between the residuals and the data in least-squares. One can further expand the second term 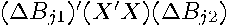 from (
20
).
from (
20
).
Fortunately, many terms in the above expression cancel which leaves a simple expression in (
21
) for the increase in error arising from restrictions.
 | (21) |
Finally, define the by matrix of cross-products of restricted least-squares regressions as 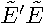 with
with 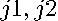 th element
th element 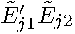 and therefore the restricted sum of squared errors,
and therefore the restricted sum of squared errors,  .
.
Computation of the unrestricted regressions means the quantities  and the Cholesky factors (even if computed from the QR algorithm) of
and the Cholesky factors (even if computed from the QR algorithm) of 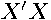 are already known. However,
are already known. However,  requires
requires 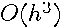 operations for its decomposition. Typically, will be small. Testing for the effect of the deletion of a single variable means equals 1 and for a variable and its associated lags equals 1 plus the number of independent variable lag terms. Since computing the increase in errors from the restrictions requires operations and resolving the first order conditions requires
operations for its decomposition. Typically, will be small. Testing for the effect of the deletion of a single variable means equals 1 and for a variable and its associated lags equals 1 plus the number of independent variable lag terms. Since computing the increase in errors from the restrictions requires operations and resolving the first order conditions requires 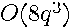 operations, deviance (i.e., likelihood ratio) tests do not depend upon and thus require very little time.
operations, deviance (i.e., likelihood ratio) tests do not depend upon and thus require very little time.
One advantage of the likelihood-based MESS methodology noted in the introduction is the ability to accommodate Bayesian extensions. An interesting point here is that Bayesian logic emphasizes the fact that the significance level should be a decreasing function of sample size. As the sample size grows, the Bayes factor region of rejection is a function of sample size, in contrast to the usual classical region which is held constant and independent of sample size. This distinction may be important for very large models of the type discussed here. The Bayes factor in favor of hypothesis  relative to hypothesis is simply the ratio of the marginal likelihoods
relative to hypothesis is simply the ratio of the marginal likelihoods  , where computation of the marginal likelihood requires
, where computation of the marginal likelihood requires  , where
, where 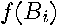 denotes the prior distribution. Leamer (1978,1983) discusses these issues.
denotes the prior distribution. Leamer (1978,1983) discusses these issues.
This suggests that efficient computation of the likelihood made possible by the matrix exponential specification may enable Bayesian approaches to hypothesis testing that allow the level of significance to vary with the sample size. Since the rejection region shrinks as the sample size grows, Bayesian testing procedures should lead to more parsimonious specifications in cases involving large sample sizes.

 See Gentle (1998, p. 166) for the standard restricted least squares estimator as well as some other techniques for computing these estimates.
See Gentle (1998, p. 166) for the standard restricted least squares estimator as well as some other techniques for computing these estimates.
